Rを用いて大阪市住民投票のいろいろなデータを探して相関関係をみる
はじめに
今回はRを用いて先に行われた大阪市住民投票の結果からいくつかのデータを探して相関分析をしてみます。今回は興味本位でいくつかのデータ探し、それらしいデータを取り込んで分析してみました。 なお、サンプルソースとデータは以下のgithubにありますので、動かして確認いただければと思います。コードはvote.Rです。
https://github.com/tokomakoma123/my_R
投票データの処理
利用データ
以下に住民投票の速報データがありましたので、これを切り取ってCSV形式にしました。
http://www.city.osaka.lg.jp/contents/wdu240/sokuho/tohyo_data_10.html
作成したCSVデータは以下の通りです。
区名,賛成,反対 北区,"36,019","25,001" 都島区,"30,135","26,671" 福島区,"21,586","17,267" 此花区,"17,597","18,872" 中央区,"24,336","20,657" 西区,"26,094","19,160" 港区,"21,410","23,351" 大正区,"16,646","21,211" 天王寺区,"18,327","20,815" 浪速区,"13,563","12,189" 西淀川区,"23,670","28,337" 淀川区,"48,566","38,903" 東淀川区,"43,388","41,340" 東成区,"20,689","20,667" 生野区,"25,396","29,190" 旭区,"23,145","28,048" 城東区,"46,728","45,784" 鶴見区,"29,859","29,752" 阿倍野区,"30,434","32,446" 住之江区,"33,184","36,880" 住吉区,"38,623","45,950" 東住吉区,"34,079","37,322" 平野区,"46,072","56,959" 西成区,"25,298","28,813"
Rのプログラム
次にこのデータを用いてRを使って処理します。
# # 得票数のデータを処理する # vote = read.csv("data/vote.csv",header=TRUE,stringsAsFactor=FALSE) vote$賛成 <- as.numeric(gsub(",", "",vote$賛成)) # 数値化する vote$反対 <- as.numeric(gsub(",", "",vote$反対)) # 数値化する vote <- transform(vote, 反対率 = (vote$差 / vote$小計) * 100) # 賛成 - 反対のグラフを描く barplot(t(vote[,5]), names.arg = vote[,1], col = c("#eeeeee"), beside = TRUE,las = 2,ylab="反対 - 賛成")
するとこんなグラフになりました。

若干Rのプログラムは違いますが、ここまでは前回同じことをやりました。
有権者数のデータを追加する
利用データ
投票データに有権者数のデータを追加します。有権者数がなぜ必要かというと、得票数は すでにわかっているのですが、投票率を知りたいからです。
実は得票率と有権者数が表になっているサイトがあることを後からしりました。
http://ja.wikipedia.org/wiki/大阪市特別区設置住民投票
でもこの中から区名と有権者数のデータを手で抜き出します。
区名 有権者数 北区 94,128 都島区 82,237 福島区 56,798 此花区 54,470 中央区 71,819 西区 70,287 港区 66,673 大正区 55,159 天王寺区 54,774 浪速区 48,936 西淀川区 75,827 淀川区 138,515 東淀川区 136,353 東成区 61,085 生野区 83,886 旭区 74,371 城東区 132,091 鶴見区 85,852 阿倍野区 85,354 住之江区 100,867 住吉区 123,549 東住吉区 105,456 平野区 155,527 西成区 90,062
Rプログラム
このデータをこれまで加工したデータにくっつけます。merge関数を使うことで2つのデータフレームを結合します。
# テーブル形式(スペース区切り)のデータを読み込む yukensya <- read.table("data/yukensya.dat",header=T) # カンマ(,)を取り除き、文字列->数値変換する yukensya$有権者数 <- as.numeric(gsub(",","",yukensya$有権者数)) # 2つのデータフレームを結合する # これまでのデータフレームと有権者のデータフレームを2つのキーでジョインする vote <- merge(x = vote, y = yukensya, by.x = "区名", by.y = "区名", all = TRUE) # 投票率を(賛成票 + 反対票) / 有権者数で計算する vote <- transform(vote, 投票率 = (vote$小計 / vote$有権者数) * 100)
年齢データを追加する
今回の投票で高齢者では反対票が多いということだったので、実際にどうかを調べるために、平均年齢の情報を探して、これまでのデータに追加します。
利用データ
データを切り出したあとで、データの出所を探したのですが、見つかりませんでした。見つかったら、このサイトを更新します。
自治体名 平均年齢 15才未満 15~64才 65才以上 大阪市西成区 52.19才 9,071人 69,435人 41,285人 大阪市生野区 47.12才 14,205人 82,742人 36,102人 大阪市旭区 46.62才 10,378人 57,478人 24,263人 大阪市大正区 46.36才 8,513人 43,058人 17,585人 大阪市東住吉区 46.19才 15,842人 80,731人 33,635人 大阪市阿倍野区 45.68才 12,864人 67,213人 25,630人 大阪市住之江区 45.35才 15,445人 82,120人 28,911人 大阪市此花区 45.30才 7,961人 41,950人 15,545人 大阪市住吉区 45.22才 19,112人 98,097人 37,393人 大阪市東成区 45.19才 9,078人 51,820人 18,577人 大阪市港区 45.04才 9,967人 54,559人 19,896人 大阪市平野区 44.42才 28,494人 122,469人 48,180人 大阪市都島区 44.24才 11,617人 69,011人 20,718人 大阪市城東区 44.08才 21,903人 106,951人 36,210人 大阪市淀川区 43.80才 18,256人 117,819人 34,061人 大阪市浪速区 43.76才 3,609人 43,967人 11,548人 大阪市西淀川区 43.76才 13,488人 62,777人 20,685人 大阪市北区 43.62才 9,077人 78,636人 20,032人 大阪市東淀川区 43.14才 19,980人 118,866人 35,775人 大阪市福島区 43.01才 7,611人 46,011人 12,785人 大阪市中央区 42.94才 6,129人 59,337人 13,215人 大阪市天王寺区 42.74才 8,588人 46,849人 12,680人 大阪市鶴見区 41.48才 18,308人 70,672人 21,539人 大阪市西区 41.04才 8,597人 61,864人 12,585人
Rのプログラム
Rでスペース区切りのデータを読み込んで処理します。結合するために区名の"大阪市"を削除したり、数値データの"才"、"人"などの文字を取り除き、数値化します。そして同じように結合しますが、 平均年齢と65才以上の人数のみ利用します。
# # 年齢データを読み込む # age <-read.table("data/age.txt",stringsAsFactor=FALSE,header=T) names(age) <- c("区","平均年齢","年齢15才未満","年齢15から64才未満","年齢65才以上") # 区のデータを整形する("大阪市"を削除する) age$区 <- substr(age$区,4,nchar(age$区)) # 不要なカンマがある場合は取り除き、数値データに変換する age$平均年齢 <- as.numeric(substr(age$平均年齢,1,nchar(age$平均年齢)-1)) age$年齢15才未満 <- as.numeric(gsub(",","",substr(age$年齢15才未満,1,nchar(age$年齢15才未満)-1))) age$年齢15から64才未満 <- as.numeric(gsub(",","",substr(age$年齢15から64才未満,1,nchar(age$年齢15から64才未満)-1))) age$年齢65才以上 <- as.numeric(gsub(",","",substr(age$年齢65才以上,1,nchar(age$年齢65才以上)-1))) #でもやっぱり平均年齢と年齢65才以上しか使わないので、不要な項目は削除する age <- age[,c(1,2,5)] #これまでのデータフレームと結合する vote <- merge(x = vote, y = age, by.x = "区名", by.y = "区", all = TRUE)
生活保護データを追加する
今の市長は生活保護に厳しいと言われているのでそのデータでも分析してみます。
利用データ
http://www.city.osaka.lg.jp/fukushi/page/0000086901.html
区 世帯数 人員 保護率(‰) 北区 2,175 2,598 21.4 都島区 2,695 3,345 32.1 福島区 762 939 13.0 此花区 2,104 2,871 43.5 中央区 1,871 2,207 24.5 西区 1,330 1,603 17.6 港区 3,313 4,298 52.5 大正区 2,835 3,856 58.3 天王寺区 1,278 1,596 21.4 浪速区 5,130 6,138 90.3 西淀川区 2,854 3,775 39.3 淀川区 5,165 6,610 37.9 東淀川区 8,025 10,993 62.8 東成区 2,990 3,781 47.3 生野区 7,462 9,330 72.2 旭区 3,648 4,743 52.5 城東区 4,198 5,500 33.3 鶴見区 2,102 3,126 27.9 阿倍野区 2,640 3,277 30.1 住之江区 4,891 6,957 56.5 住吉区 7,392 9,926 64.2 東住吉区 6,751 8,588 66.7 平野区 9,535 13,738 69.9 西成区 25,293 27,793 235.6
Rプログラム
保護人員数と有権者数で保護率を算出します。そして結合します。
# # 各区の生活保護データを読む # http://www.city.osaka.lg.jp/fukushi/page/0000086901.html hogo <-read.table("data/hogo.txt",head=T) names(hogo) <- c("区","保護世帯数", "保護人員数", "保護率") hogo <- hogo[,1:4] #カンマを削除し、数値データに変換する hogo$保護世帯数 <- as.numeric(gsub(",","",hogo$保護世帯数)) hogo$保護人員数 <- as.numeric(gsub(",","",hogo$保護人員数)) hogo$保護率 <- as.numeric(gsub(",","",hogo$保護率)) #これまでのデータフレームにマージする vote <- merge(x = vote, y = hogo[,c(1,3)], by.x = "区名", by.y = "区", all = TRUE) vote <- transform(vote, 保護率 = (vote$保護人員数 / vote$有権者数) * 100)
人口の統計データを追加する
利用データ
人口に関するデータを以下のサイトから取り出します。
http://www.city.osaka.lg.jp/shimin/cmsfiles/contents/0000130/130263/shiryou05-1.pdf
区名 世帯数 総数 男 女 1世帯あたり人員 人口密度 面積 北区 59,377 105,204 50,937 54,267 1.77 10,184 10.33 都島区 48,769 102,062 49,720 52,342 2.09 16,870 6.05 福島区 31,819 63,670 30,271 33,399 2.00 13,634 4.67 此花区 29,142 64,914 31,518 33,396 2.23 3,997 16.24 中央区 45,349 73,259 34,131 39,128 1.62 8,250 8.88 西区 46,431 78,342 37,180 41,162 1.69 15,066 5.20 港区 39,255 83,796 40,969 42,827 2.13 10,607 7.90 大正区 31,115 71,433 35,170 36,263 2.30 7,575 9.43 天王寺区 32,838 66,772 31,019 35,753 2.03 13,911 4.80 浪速区 37,432 57,936 29,911 28,025 1.55 13,258 4.37 西淀川区 41,957 96,142 47,550 48,592 2.29 6,756 14.23 淀川区 88,844 170,949 84,794 86,155 1.92 13,524 12.64 東淀川区 91,973 177,952 88,643 89,309 1.93 13,430 13.25 東成区 37,714 78,951 37,664 41,287 2.09 17,352 4.55 生野区 62,669 134,988 64,514 70,474 2.15 16,108 8.38 旭区 44,188 93,732 44,900 48,832 2.12 14,878 6.30 城東区 74,931 164,824 78,909 85,915 2.20 19,575 8.42 鶴見区 44,677 110,148 53,097 57,051 2.47 13,499 8.16 阿倍野区 48,934 107,779 50,063 57,716 2.20 17,993 5.99 住之江区 55,758 127,892 61,456 66,436 2.29 6,158 20.77 住吉区 73,491 157,085 73,780 83,305 2.14 16,819 9.34 東住吉区 61,637 133,985 63,679 70,306 2.17 13,742 9.75 平野区 86,791 200,483 95,527 104,956 2.31 13,103 15.30 西成区 74,297 129,801 76,573 53,228 1.75 17,660 7.35
Rプログラム
同様に男女で賛成、反対の票と関係があるかを分析するために男女比率を求めます。あと、1世帯あたりの人員数、人口密度も分析に利用するので、これらのデータをこれまでのデータにマージします。
# 人口の統計データをマージする #http://www.city.osaka.lg.jp/shimin/cmsfiles/contents/0000130/130263/shiryou05-1.pdf # 遅まきながら、数値データからカンマを取り去って数値化する関数を追加する to.numeric <- function(str) { return (as.numeric(gsub(",","",str))) } city <- read.table("data/city.dat",header=T) city$世帯数 = to.numeric(city$世帯数) city$総数 = to.numeric(city$総数) city$男 = to.numeric(city$男) city$女 = to.numeric(city$女) city$1世帯あたり人員 = to.numeric(city$1世帯あたり人員) city$人口密度 = to.numeric(city$人口密度) city$面積 = to.numeric(city$面積) city <- transform(city, 男性比率 = (city$男 /city$総数) * 100) city <- city[,c(1,3,6,7,9)] vote <- merge(x = vote, y = city, by.x = "区名", by.y = "区名", all = TRUE)
収入のデータを追加する
利用データ
大阪府の年収1000万円世帯比率と平均年収(2014/6/23記事)というのがあるのでこのデータを利用します。 http://media.yucasee.jp/posts/index/14177/2
区名 平均年収 高額年収比率 天王寺区 509万円 9.85% 福島区 455万円 5.17% 西区 451万円 5.94% 都島区 443万円 6.46% 鶴見区 443万円 4.39% 旭区 441万円 6.76% 西淀川区 436万円 3.81% 北区 433万円 4.96% 阿倍野区 426万円 9.40% 淀川区 426万円 4.76% 中央区 423万円 5.05% 城東区 423万円 5.05% 東成区 416万円 5.19% 住之江区 411万円 4.77% 東住吉区 402万円 5.40% 住吉区 393万円 4.14% 港区 389万円 3.26% 大正区 382万円 3.27% 東淀川区 371万円 3.09% 浪速区 369万円 4.12% 平野区 366万円 3.22% 此花区 365万円 2.93% 生野区 356万円 3.31% 西成区 266万円 1.13%
Rプログラム
平均収入と高額年収比率を分析で利用するために追加します。
income <- read.table("data/income.dat",stringsAsFactor=FALSE,header=T) income$平均年収 <- to.numeric(substr(income$平均年収,1,nchar(income$平均年収)-2)) income$高額年収比率 <- to.numeric(substr(income$高額年収比率,1,nchar(income$高額年収比率)-1)) vote <- merge(x = vote, y = income, by.x = "区名", by.y = "区名", all = TRUE)
利用するデータを個別にグラフ化する
利用するデータを視覚化します。分かりやすくするために順番にソートしてから表示します。
反対票 - 賛成票
x <- vote[with(vote,order(-vote$差)),] barplot(x$差, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,main='差')

平野区、住吉区、旭区が反対票が多く、北区、淀川区、西区が賛成票が多いです。
反対票率
x <- vote[with(vote,order(-vote$反対率)),] barplot(x$反対率, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,main='反対率')

有権者数で割って率に直すと、反対は大正区、平野区、旭区になり、賛成は北区、西区、福島区となります。
保護率
x <- vote[with(vote,order(-vote$保護率)),] barplot(x$保護率, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,main='保護率')
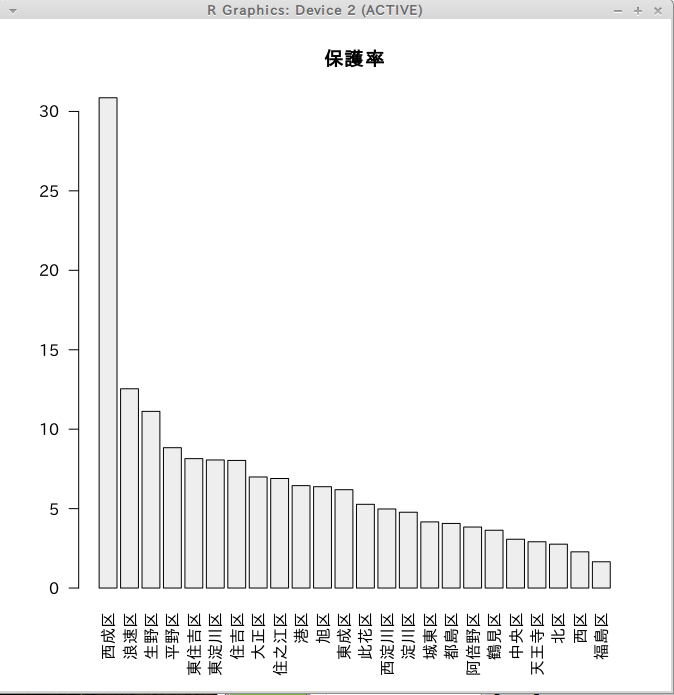
生活保護率は圧倒的に西成区が多く、浪速区、生野区、平野区になります。 少ないのは福島区、西区、北区です。
投票率
x <- vote[with(vote,order(-vote$投票率)),] barplot(x$投票率, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,xlab='区',ylab='投票率',main='投票率')

投票率はさほど大きな差は見られませんが、阿倍野区、天王寺区、城東区が高く、浪速区、西成区、東淀川区が低いです。
平均年齢
x <- vote[with(vote,order(-vote$平均年齢)),] barplot(x$平均年齢, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,xlab='区',ylab='平均年齢',main='平均年齢')

平均年齢は西成区が突出して高く、そのあとは生野区、旭区、大正区が続きます。若いのは西区、鶴見区、天王寺区です。
年齢65才以上の人口
x <- vote[with(vote,order(-vote$年齢65才以上)),] barplot(x$年齢65才以上, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,xlab='区',ylab='年齢65才以上',main='年齢65才以上')

平均年齢よりも65才以上の数には差が見られます。平野区、西成区、住吉区でこの年齢層の数が多いです。浪速区、西区、天王寺区は少ないです。
1世帯あたりの人員数
x <- vote[with(vote,order(-vote$1世帯あたり人員)),] barplot(x$1世帯あたり人員, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,xlab='区',ylab='1世帯あたり人員',main='1世帯あたり人員')

世帯あたりの人員数は鶴見区、平野区、大正区が多いです。少ないのは浪速区、中央区、西区です。
人口密度
x <- vote[with(vote,order(-vote$人口密度)),] barplot(x$人口密度, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,xlab='区',ylab='人口密度',main='人口密度')

人口密度は城東区、阿倍野区、西成区が高く、此花区、住之江区、西淀川区が低いです。
男性比率
x <- vote[with(vote,order(-vote$男性比率)),] barplot(x$男性比率, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,xlab='区',ylab='男性比率',main='男性比率')

こちらは西成区、浪速区、東淀川区が高いですが、東淀川区以降はさほど変わりません。低いのは阿倍野区、天王寺区、中央区です。
平均年収
x <- vote[with(vote,order(-vote$平均年収)),] barplot(x$平均年収, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,xlab='区',ylab='平均年収',main='平均年収')

平均年収の突出しているのは天王寺区でその後、福島区、西区が続きます。 逆に低いのは西成区、生野区、此花区です。
年収1000万以上の高額年収比率
x <- vote[with(vote,order(-vote$高額年収比率)),] barplot(x$高額年収比率, names.arg = x[,1], col = c("#eeeeee"), beside = TRUE,las = 2,xlab='区',ylab='高額年収比率',main='高額平均比率')

天王寺区、阿倍野区が突出しており、旭区が続きます。低いのは西成区が抜けており、此花区、東淀川区になります。
相関を計算してグラフ化する
これらのデータから相関のグラフを描きます。相関はcor(x,y)で求めることが出来ます。相関は一般的に0.7以上が強い相関、0.4以上は相関がある、0.2以上で弱い相関関係となります。
parで3 x 3のプロット領域を確保し、その中に9個の相関グラフを描きます。
par(mfrow=c(3,3)) # 1. 反対率と平均年齢の相関グラフを描く x <- vote$反対率 y <- vote$平均年齢 plot(x, y,xlab='反対率',ylab='平均年齢',pch=16, main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x)) # 2. 反対率と65才以上の比率の相関グラフを描く x <- vote$反対率 y <- vote$年齢65才以上/vote$総数 plot(x, y,xlab='反対率',ylab='年齢65才以上',pch=16, main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x)) # 3. 反対率と平均年齢の相関グラフを描く x <- vote$反対率 y <- vote$保護率 plot(x, y, xlab='反対率',ylab='保護率',pch=16, main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x)) # 4. 反対率と生活保護率の相関グラフを描く x <- vote$反対率 y <- vote$投票率 plot(x, y, pch=16, xlab='反対率',ylab='投票率',main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x)) # 5. 反対率と世帯あたりの人員数の相関グラフを描く x <- vote$反対率 y <- vote$1世帯あたり人員 plot(x, y, pch=16, xlab='反対率',ylab='1世帯あたり人員',main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x)) # 6. 反対率と人口密度の相関グラフを描く x <- vote$反対率 y <- vote$人口密度 plot(x, y, pch=16, xlab='反対率',ylab='人口密度',main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x)) # 7. 反対率と男性比率の相関グラフを描く x <- vote$反対率 y <- vote$男性比率 plot(x, y, pch=16, xlab='反対率',ylab='男性比率',main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x)) # 8. 反対率と平均年収の相関グラフを描く x <- vote$反対率 y <- vote$平均年収 plot(x, y, pch=16, xlab='反対率',ylab='平均年収',main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x)) # 9.反対率と高額年収比率(年収1000万円以上の割合)の相関グラフを描く x <- vote$反対率 y <- vote$高額年収比率 plot(x, y, pch=16, xlab='反対率',ylab='高額年収比率',main=sprintf("相関係数 = %5.3f",cor(x,y))); abline(lm(y ~ x))

年齢65才以上の人口/総人口つまり年齢65才以上の占める割合の多い区で反対票が多いことが分かりました。この相関係数は0.7近いもので強い相関が認められます。
つぎに家族の人員構成も0.636とそれなりに強い相関があることにあります。大きな家族を持つ区ほど反対の割合が多いことになるということです。
平均年齢と反対率もそれなりの相関をもつことが分かりました。 その後、保護率、投票率が続きます。
逆相関が見られるのは平均年収です。つまり年収が高い区ほど賛成に投じた割合が高いのです。
おわりに
今回ははじめてRを使って実際のデータの分析を行いました。統計の初学者でRもはじめたばかりですので、分析結果にはおかしいところがあるかも知れません。でも興味のある事象に関して自分でデータを収集して実際に分析を行うことは好奇心がそそられます。また、実践力の観点でもプラスになるかと思います。今後もこのような取り組みを行なって行きたいと思います。